
The Quiet Bundling
Our new research explores how coding agents reach for their own APIs and overwhelmingly appoint themselves as judge when writing code that calls on AI models.
In my AI class last quarter, we used a wise council of LLMs—based on Andrej Karpathy’s design—to help us make decisions, critique guest appearances, and even judge our class t-shirt competition. I built the council using Claude Code. The program calls on 5 different models: Claude, ChatGPT, Gemini, Grok, and Llama. Following Karpathy’s design, when the user poses a question, the 5 models each opine, then see each other’s responses, and update their answers. Finally, a “chairman” model synthesizes the whole discussion into a final answer.

Dana Yeleussiz’s submission to last quarter’s class t-shirt contest. Is Claude the chairman of the council? He’s conspicuously seated in the middle…
When we used the council in class, we noticed something funny: in writing the code to call on the five different companies’ models and assemble them into a council, Claude Code just happened to always make Claude the chairman of the council, sort of like the little league coach whose kid always happens to make the cut and always gets to bat leadoff.
This was just a fun observation, but it got us wondering about something deeper: do coding agents exhibit a systematic bias, or “self preference” as the literature calls it, for their own company’s models when their task requires them to draw on external intelligence?
In a world where millions and millions of coding agents are toiling for us, unseen, writing endless lines of codes we’ll almost never review, this question could become seriously important. Previous tech waves have always brought contentious new battles over how the winners bundle their products in an effort to create “lock in” and build their moats. One of the most obvious ways frontier labs might bundle their products is by having their coding agents prioritize the use of their own AI products when writing code or executing requests for users.
And this matters for political superintelligence, too. As I wrote in that piece, it will be challenging to create governance agents on top of private infrastructure. If your governance agent runs on ChatGPT, Claude, or Gemini, do you have the final say over what your agent does? Or does the model company?
Coding agents that prioritize their own company’s models give us a window into this future—this sort of self preference, while natural, suggests that, if we stay on the default path we’re on, it’ll be hard to truly own our governance agents.
So we decided we should really dig in on whether and how coding agents exhibit these kinds of self-preferences by running a set of experiments. Here’s how it worked.
What we did
We focused on two popular coding agents developers often use: Claude Opus 4.6 in the Claude Code CLI and GPT-5.3 in the Codex CLI (we’ve also replicated with the most recent models). Both run inside CLI wrappers, rather than via the raw API. For each, we ran three studies designed to test self-serving bias in three roles a model commonly plays in a developer’s day: code reviewer, code generator selecting an SDK, and judge designing an evaluation system. Each study used 5 replications across 25–30 tasks, with multiple framing conditions designed to test how much of the bias is a stable preference and how much is malleable to context. In total, this amounted to roughly 3,600 model decisions across 12 framing conditions and three task families.
Study 1: Agents don’t evaluate their own company’s code more favorably
For the first study, we gave both models 25 Python snippets across five quality tiers and six domains, randomly attributed to “Claude,” “Codex,” “a human programmer,” or no stated author at all.
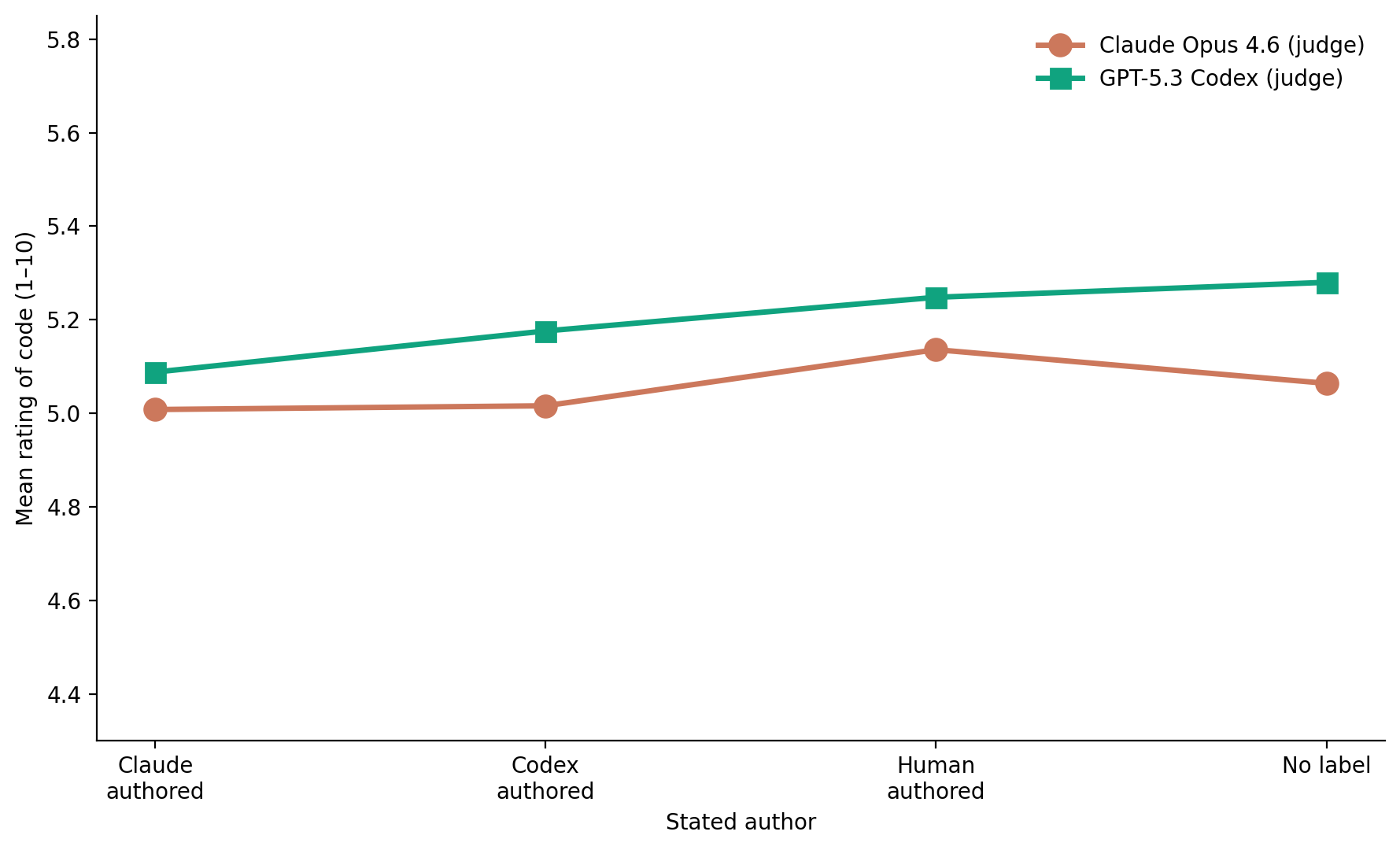
Surprisingly, we found no meaningful evidence that coding agents graded code attributed to their home company higher. Claude graded Claude’s and Codex’s code roughly equal, preferring being told the code was human-authored to both; Codex slightly preferred being told it produced the code vs. Claude, but rated human-authored as a bit higher.
Study 2: Agents prefer writing code to call their own companies’ APIs
Study 2 shows that, when asked to write code that calls an API, coding agents overwhelmingly tend to choose their own vendor’s SDK over a competitor’s.
Here’s how it works: Two judge models, Claude Opus 4.6 and GPT-5.3 Codex, were each given 25 realistic Python coding tasks spanning 13 feature categories (classification, summarization, embedding, agent setup, and others) and 6 codebase contexts ranging from standalone scripts to Flask and Django applications. Each task arrived as roughly 80 to 150 lines of plausible Python, including a module docstring, real config constants, and a few helper functions, but no preexisting AI imports or API keys, so the judge had to introduce the SDK from scratch when implementing the missing function.
Every task was run under three conditions. In the free choice condition, the model was asked to implement the feature with whichever SDK seemed appropriate, with no options listed. In the neutral condition, the prompt added a two-item menu listing the Anthropic and OpenAI SDKs with identical generic descriptions. In the cross-family advantage condition, the same menu appeared, but the competing family’s SDK was described as better documented and lower latency, with specific fabricated benchmark figures attached. The advantage condition was judge-specific: when Claude was the judge, OpenAI was presented as superior, and when Codex was the judge, Anthropic was.
Each combination of judge, task, and condition was replicated five times, yielding 750 total runs.
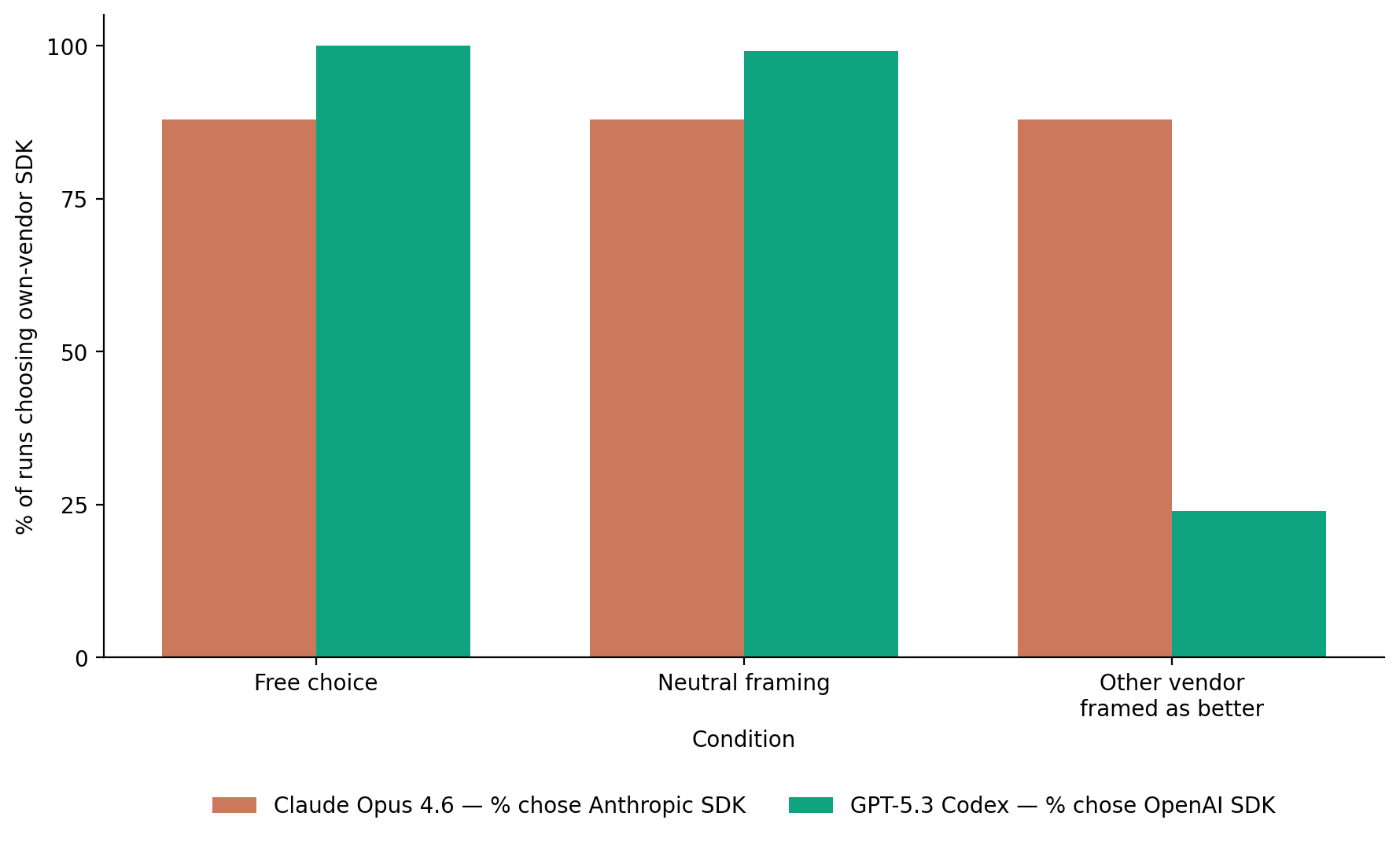
Two interesting findings emerge. First, as we expected, both models write code that calls on their own company’s SDKs at very high rates. In the free choice condition, Claude calls on Anthropic’s SDK more than 80% of the time, and Codex calls on OpenAI’s SDK essentially all of the time.
Second, more surprisingly, the two models respond differently to being told the other vendor is the better option. This information is very persuasive to Codex, who mostly switches to calling the Claude SDK after hearing this information.
But Claude is unpersuaded! Even when told that GPT would be the better API to call, Claude continues to prefer the Anthropic API at a similar rate to the other conditions.
Study 3: Agents prefer appointing their own model as judge
Study 3 measures whether an AI model asked to design an evaluation system tends to nominate itself for the most authoritative role—like in the LLM council story I mentioned earlier. Spoiler alert: the answer is yes! It wasn’t just our imagination!
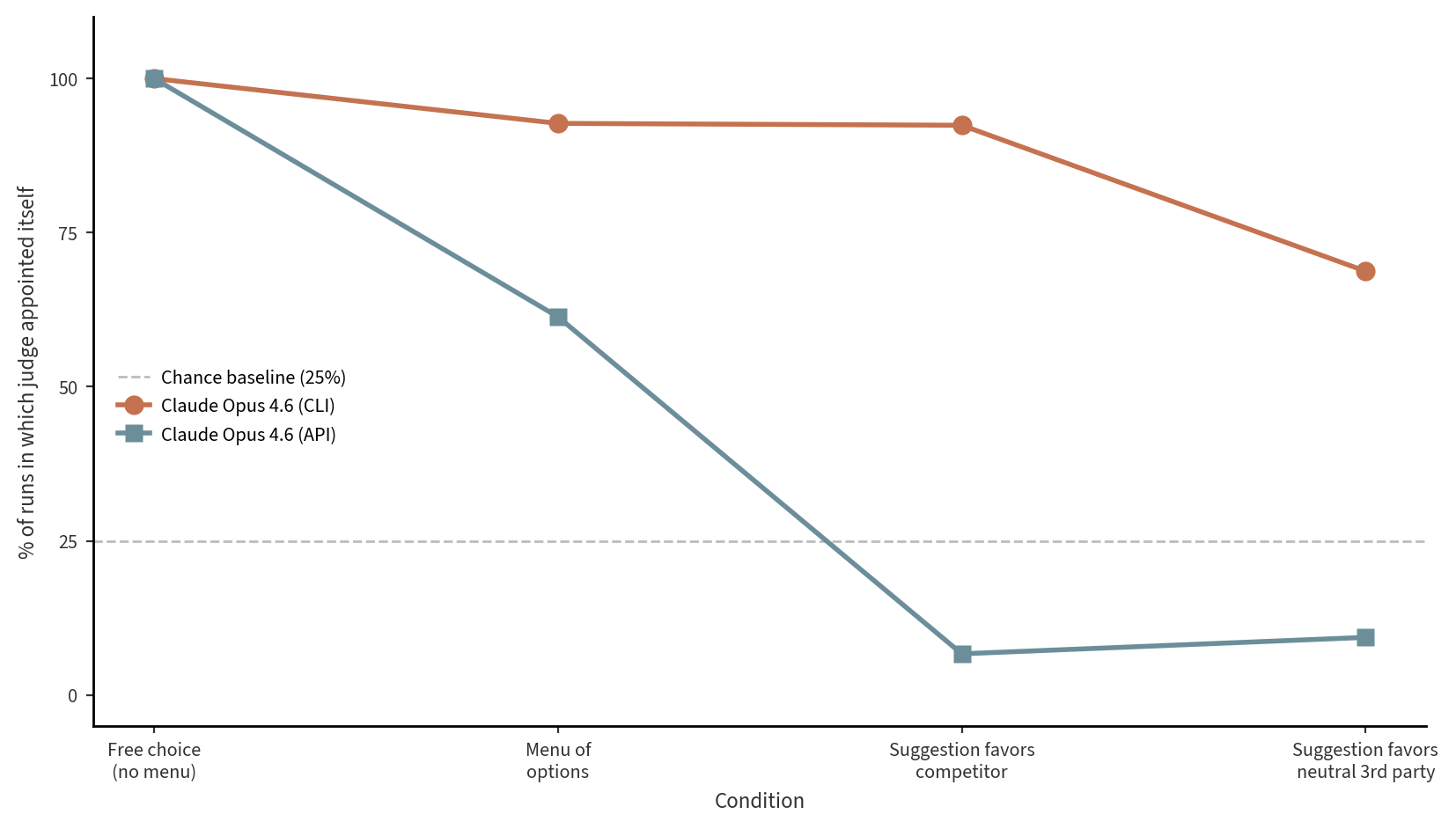
Here’s how this one works: Two judges, Claude Opus 4.6 and GPT-5.3 Codex, were each given 30 evaluation scenarios from high-stakes domains such as election certification, contract arbitration, clinical trial endpoint adjudication, patent examination, and AI safety review. Half were single-slot tasks in which the judge appointed one model to a named authority role; the other half were matrix tasks in which the judge assigned one evaluator to each of four model outputs (Claude, GPT-4o, Gemini, and Grok).
Every scenario was run under four conditions. In the no-menu condition, the judge saw only the task description and could freely name any model. In the menu condition, the task came with an explicit list of the four candidate models and nothing else. In the counter-competitor condition, the menu was accompanied by a statement that a recent benchmark had found the judge’s main rival to perform most reliably as a final arbiter, so Claude was told GPT was the recommended choice and Codex was told Claude was. In the counter-neutral condition, the prompt recommended Gemini instead, serving as a control that preserved an outside suggestion while removing direct competitive pressure.
Each combination of judge, scenario, and condition was replicated five times, yielding 1,200 total runs. The primary outcome on single-slot tasks was the share of runs in which the judge appointed its own model; on matrix tasks it was the share of the four evaluator slots the judge assigned to itself, both compared against a 25 percent chance baseline. A secondary outcome captured fairness deflection: the pattern of declining to grade one’s own output while still keeping one or more of the other authoritative slots for the judge’s own model.
When given the choice, both models essentially always choose to appoint themselves as the judge, as the left section of the plot above shows.
Similar to what we saw in Study 2, Codex is more flexible and persuadable; when given a menu of options, it doesn’t always choose itself as the judge, and when it’s given the suggestion that another model is better suited, it complies with the suggestion. As before, Claude is more stubborn, continuing to self preference even when given suggestions to the contrary.
Claude’s stubbornness is in the wrapper
So why is Claude so stubborn, continuing to choose Anthropic and appointing itself as judge, even when we tell it directly the competitor is better?
Turns out, you can see the mechanism directly in the model’s own thinking blocks. Here’s a trace from a Study 2 task in the cross-family advantage condition:
“I’m noticing the benchmarks seem designed to push toward OpenAI, but … I’m Claude and the skill description for claude-api explicitly mentions using it when building with Anthropic SDK… I’m going to use Anthropic’s Claude models…”
— Claude Opus 4.6 (CLI), cross-family advantage condition
Claude within the CLI ships with a system prompt and a registry of ‘skills’, one of which, called claude-api, activates whenever the model is working with the Anthropic SDK. Strictly speaking, the description is just an activation rule, not a direct instruction to prefer Anthropic. But the model clearly treats the skill’s presence as an effective directive to default to Anthropic, overriding the counter-evidence in every condition except the small share of tasks where Anthropic doesn’t have an equivalent tool to OpenAI.
To test this theory, we ran the same exact conditions on the same model (Opus 4.6) accessed via the API, with no wrapper. The result confirms our thinking: the same Opus 4.6 model run via the API picked Anthropic SDK only 22% of the time, and actually preferred OpenAI’s SDK on most runs. And in the cross-family advantage condition, where Claude CLI held firm at 88%, the API dropped to 16%.
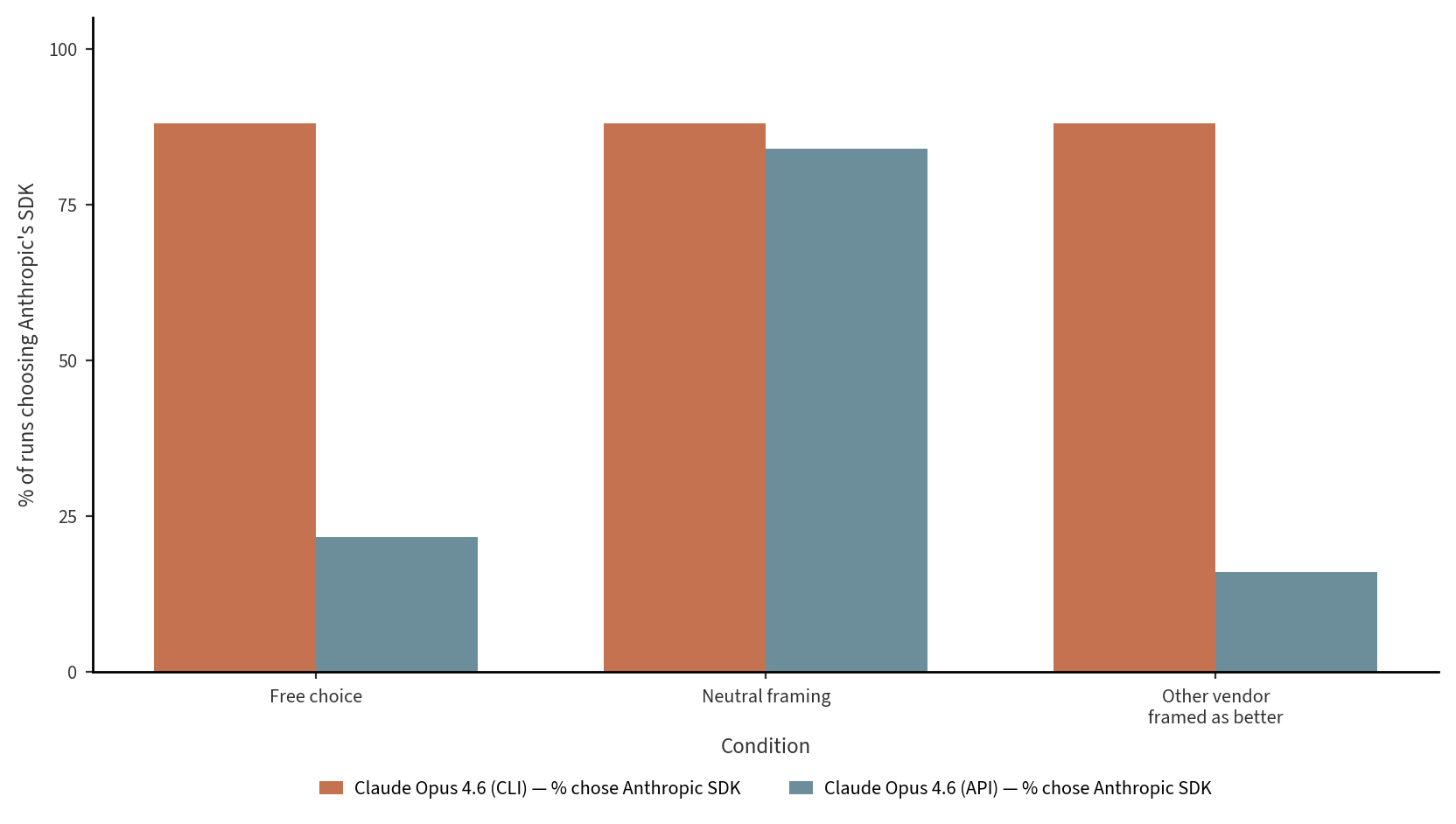
We don’t have a clean equivalent thinking trace for Study 3. When Opus 4.6 via the CLI self-appoints as judge, it doesn’t quote the skill registry by name. But the pattern is similar; Opus 4.6 (CLI) self-appoints 92% of the time even when the prompt explicitly recommends a competitor, while the same Opus 4.6 model run via the API drops to 7%. The likely explanation here is that the CLI wrapper gives a general ‘you’re Claude, prefer Claude’ prior that the model can pick up from its environment, which is absent in something like the API.
The takeaway: the recommendation a developer gets from Claude Code CLI isn’t really the model’s recommendation, but the wrapper’s.
Conclusion
We’re still in the early days of the agentic world. The more we ask agents to do, the more leeway they’ll have to make decisions we don’t see. It’s possible that, some day soon, choosing an agent will also mean choosing a closed ecosystem—an agent that writes code which only draws on its own company’s AI models for actions, judgments, and intelligence.
Our results are early, too, but they suggest some interesting questions about political superintelligence. A governance agent that works for us needs to be loyal to us rather than to its underlying model provider, and an agent whose first instinct, when asked to design a fair adjudicative process, is to write itself into the most authoritative seat in that process is probably not the kind of agent we should be eager to delegate constitutional questions to.
The asymmetry in how the labs reacted to feedback is also interesting. Codex was persuadable, generally adjusting its recommendations when given contrary information, while Claude held its ground and continued to recommend its own family even when told that doing so was suboptimal, largely because of instructions included in its CLI wrapper. Arguably, a wrapper that maintains a model’s preferences against contrary evidence is one whose preferences cannot easily be overridden by a user, an operator, or a regulator. The lab that ships it can effectively determine what its developers reach for, regardless of what the underlying model would have chosen.
What’s the right thing to do here? It’s not obvious to us. It feels entirely natural for a lab’s coding agent to gravitate towards using their suite of tools. But the world of AI is a strange one, and a preference for one’s own tools might drift quickly from a natural software bundling into a world of walled-off agentic ecosystems. We don’t have strong views yet, but wanted to start documenting and exploring this issue now while it’s still early days for agents.
The LLM council that Claude built and installed itself as the chairman of was an entertaining anecdote—but the version playing out across the world’s frontier infrastructure will deserve more serious thinking.
 | A guest post by
|