
An agentic experiment in Texas
How we beat the markets in calling the Texas primaries, and what it tells us about the future of political forecasting
A critical pre-requisite to staying free in the AI era will be to redesign our information ecosystems. In a world awash with content and competing narratives, the task of keeping informed about what’s actually happening in the world and what it means becomes crucial.
Nowhere does this matter more than in the political sphere. Can AI make us smarter about politics? And can we make AI smarter about politics in return? These questions cut to the core of our work here at Free Systems.
There has been a lingering sense that something is broken in how we currently understand elections in real time. Polls have been getting shaky for years, and recent research suggests the problem is getting worse—AI can now defeat the human-verification checks that pollsters use to screen out fake survey responses, which means response quality may deteriorate further just as the stakes rise.
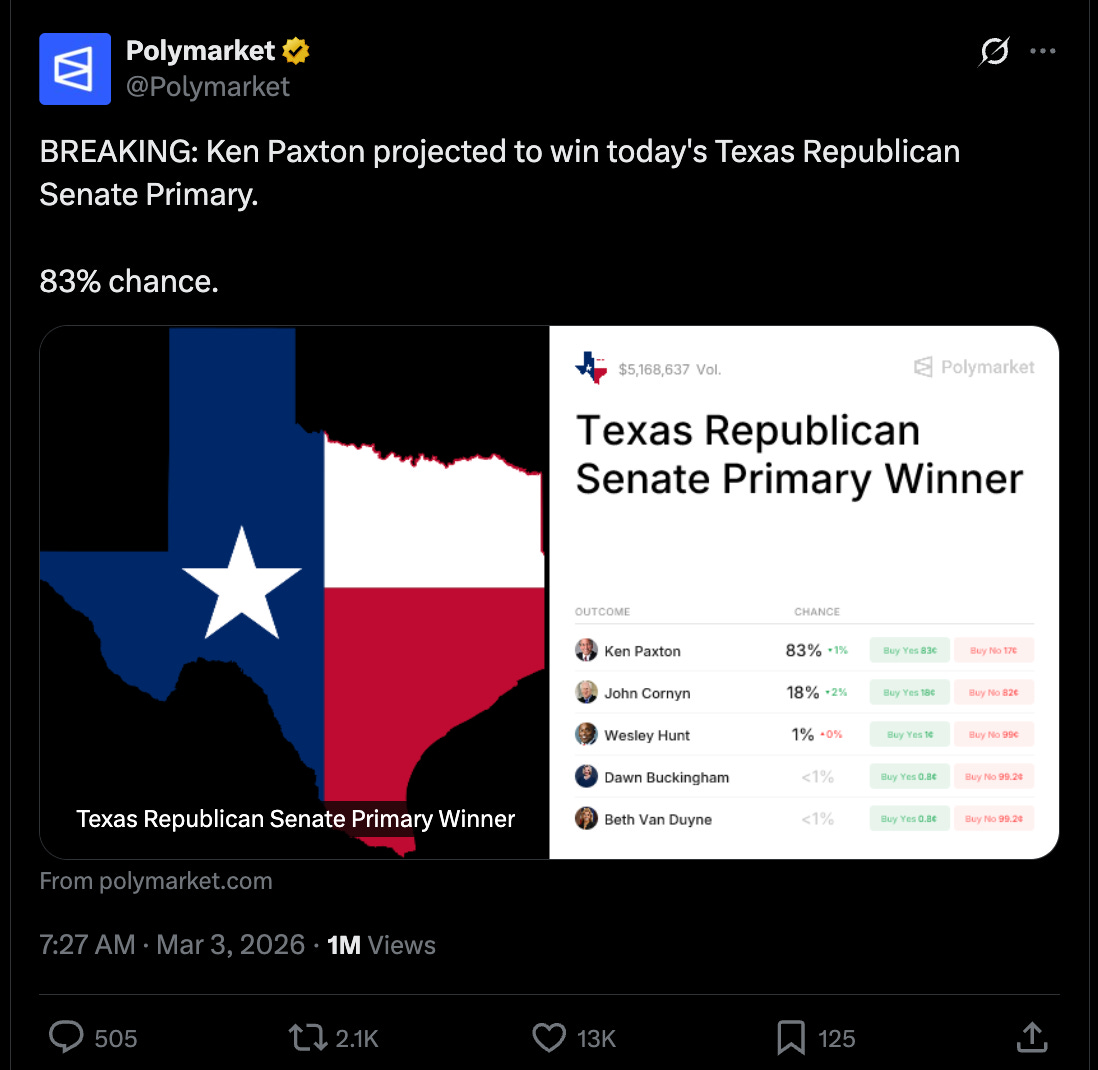
Prediction markets had their big breakout moment during the 2024 election and are supposed to help, but they’re shaky too. On the morning of the Texas Republican Senate primary last week, Polymarket tweeted “BREAKING: Ken Paxton projected to win today’s Texas Republican Senate Primary.” Just hours later, the results confirmed him in second place.
That brings us to the 2026 elections, and how we monitor them. The midterms promise to feature the most prediction-market volume for Congressional elections in history. They will also be the first major US elections to be held in the presence of supercapable frontier AI models who are now closely competing with the best human forecasters.
The Democrats are overwhelmingly favored to romp to victory in the House in 2026, but even so, the closest, most competitive races in the midterm elections—not just in the House but in the Senate and in a variety of statewide and local races—will be hard to call. It will be hard to know what’s what on Election Night, and candidates will step into the vacuum to make their own claims about what happened and who won. Decision desks will be crucial, but will only speak loudly to the most salient national races.
So can AI fix this? Can we build something that actually knows what’s happening on election night, faster than the markets, before misinformation takes hold? Or will it further muddy the waters with a flood of plausible-sounding analysis that’s impossible to verify in real time? Just as some politicians try to do the very same thing?
Last week, we looked to Texas to try to find out.
Everything to play for in the Lone Star state
These primaries gave us an excellent testing ground for these questions. They featured two closely contested senatorial primaries with major implications for November and, consequently, lots of public attention. Combined ad spending approached $99 million, making them the most expensive Senate primaries in Texas history.
On the Republican side, Attorney General Ken Paxton was the overwhelming market favorite. Kalshi had him at 82%. Polymarket had him at 83%. Paxton himself had predicted he’d win outright and avoid a runoff.
Meanwhile, the polls told a very different story. The RealClearPolitics average had it Paxton +2.3, with Paxton at 37.3% and Cornyn at 35% in the head-to-head. The final Emerson poll had Paxton at 40%, Cornyn at 36%, and Hunt at 17%. The UT/Texas Politics Project poll had it even tighter: Paxton 36%, Cornyn 34%, Hunt 26%. The markets were pricing a Paxton blowout. The polls suggested a messy three-way race where no one was close to 50%.

On the Democratic side, the picture was murkier. The markets had Talarico at 75% on Kalshi, but the RCP average was nearly a dead heat: Talarico 49.3%, Crockett 47.7%. The UT poll actually had Crockett ahead, 56-44. The markets and polls agreed Talarico was favored, but the margin was genuinely uncertain.
A new set of tools
This was all set up perfectly to answer our core question: when the polls and the markets disagree, and nobody really knows what’s going to happen, can AI help you figure it out before everyone else does?
When people talk about AI transforming research and forecasting, the image is usually autonomous: agents that gather information, reason independently, and produce outputs without human involvement. That’s the dream behind systems like Bridgewater’s AIA Forecaster, which spawns multiple AI agents to independently research questions, reconcile disagreements, and produce probability estimates that rival human superforecasters on standard benchmarks. No experts required. Just models, data, and speed.
This ‘recursive-self improvement’ loop may be increasingly powerful in coding tasks, but our experiment in last week’s election shows that it has some ways to go in the political sphere. The agents we tested produced plausible-sounding reasoning that was too slow for fast-moving markets and, in some cases, genuinely nonsensical once you understood the actual political dynamics. One went down a rabbit hole arguing why a Democratic Senate nomination in Texas justified buying Trump impeachment contracts because it would shift Senate control. They were reasoning from surface patterns, not political understanding.
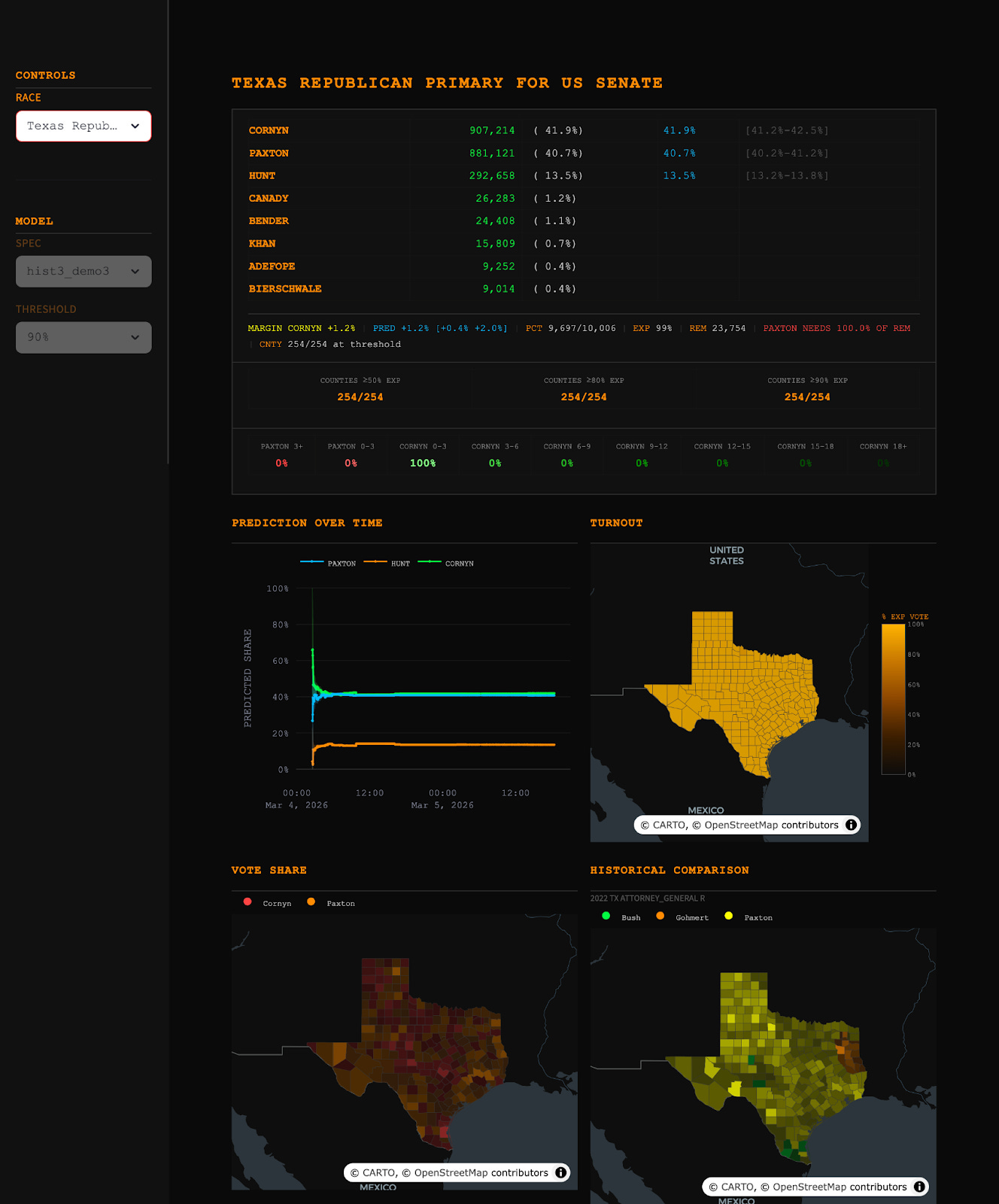
What actually helped us beat the markets was different—and, we think, more important. Dan Thompson and I took our proprietary statistical model, built on years of research into American elections, and used Claude Code to build a live trading dashboard around it in an hour or two.
Claude didn’t analyze the election or develop the statistical approach, it built an infrastructure that let two political scientists deploy their expertise at the speed the market demanded. Claude helped us to pull live county-level election returns as they came in, run our statistical models in real time, and adapt their output to give us live intelligence on how the election was unfolding.
The human experts with AI tooling crushed the autonomous agents in our trial. This is a lesson that might well generalize to lots of other tasks that require researcher expertise combined with coding- like academic research, corporate data science, and so on. It also resonates for the 2026 midterms. If we want to know what’s going on in close races up and down the ballot, we should have political data analysts equipped with AI coding agents tracking the latest data to help suss out what’s happening in real time.
A step change in forecasting infrastructure
A lot has changed since I flew to New York for the off-cycle elections in New York and New Jersey and joined a group of academics, technologists, and prediction market traders to trade live on election night. I wrote about that experience in my first newsletter post.
We had a good statistical model for that experiment. The problem was everything around it. We wanted to build a live dashboard that could ingest county-level returns, run them through our model, and translate the outputs into trading signals in real time. We never got there. Building that kind of infrastructure takes real engineering work, and we ran out of time. So we spent election night watching returns on one screen, doing mental math on another, and making trades based on a rough sense of what our model was telling us rather than a precise, live view.
It was a useful learning experience, but the results were mixed. We made some good calls and some bad ones. The bottleneck wasn’t the model. It was the fact that we couldn’t act on what the model was telling us fast enough. By the time we’d manually processed the latest county results and figured out what they meant for our positions, the market had often already moved.
Four months later, that has changed completely.
Using Claude Code, Dan and I built the entire dashboard in an hour or two—-a fraction of what it would have taken before. It pulled in live county-level results, ran them through our model, and displayed everything we needed in real time: margin estimates, confidence intervals, outstanding vote by county, and—-after a ten-minute conversation with Claude just before polls closed—-a live translation of our predictions into the specific margin bins the Kalshi contracts used.
You can check out a video of the tool in action here.

The model itself is the same kind of statistical model we used in November. Our model pipeline ingests granular demographics and historical data on election results, matches it up with realtime election results on election night, predicts the realtime results in places with a substantial share of data using the historical and demographic data, then imputes the results in the rest of the state where votes are still being counted. This approach is similar to how news organizations use data to decide when to declare one candidate the victor.
The point is that the model and the domain expertise has been consistent over time, but what changed was the infrastructure around it. In November, the gap between having a good model and being able to act on it in real time was an engineering problem we couldn’t quickly solve. Just months later, Claude Code has made that problem trivial.
Here’s an example: just before polls closed, we realized that it would be helpful to translate the vote share predictions of our model into statistical predictions about the specific bins that the Kalshi contracts used (e.g., Paxton by 0-3 percentage points, Paxton by 3-6, and so forth). Within minutes, after a quick chat with our friend Claude, the dashboard was updated to display this information in real time as data came into our model. The cost of turning expertise into infrastructure has completely collapsed.
How our model held strong in the Republican primary
Back to the Texas polls. They closed at 7 PM Central, 5 PM Pacific. The first Republican results dropped at 5:15 PM, and John Cornyn was already leading by 8.6 points.
The market didn’t believe it. Ken Paxton had been trading at 82% to win the nomination all day. When the early returns showed Cornyn ahead, the margin-of-victory contracts barely moved. The implicit assumption was that this was an artifact of which counties had reported first and would wash out as Paxton’s strongholds came in, which is not a crazy idea at all.
But our model and dashboard said otherwise. The early returns were broadly consistent with a narrow Cornyn win. Not a blowout, but a lead that would hold. We bought the Cornyn 0-3% bin for 20 cents a share.
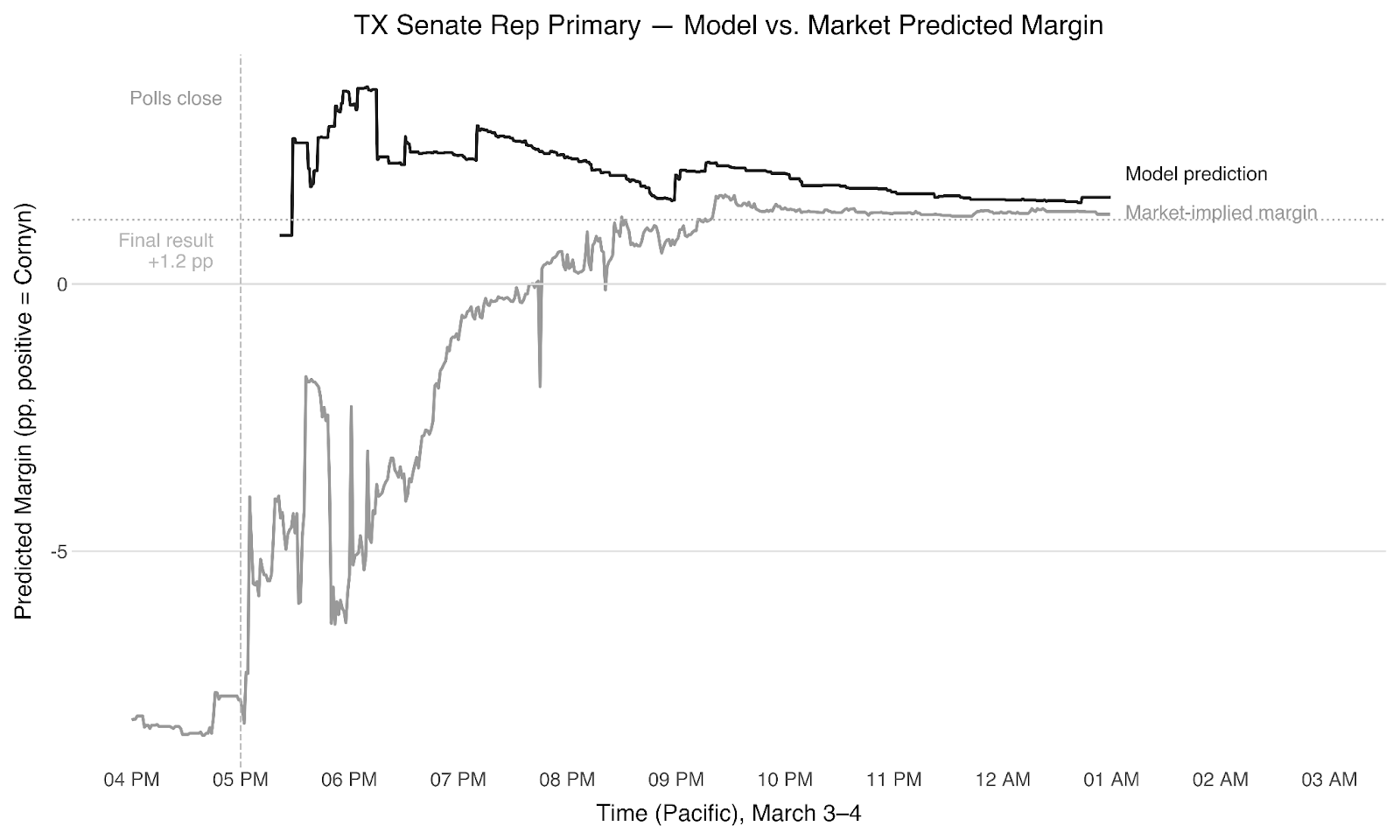
Over the next two hours, Montgomery County—Paxton’s strongest base—dropped big batches at Paxton +35, grinding Cornyn’s lead from 8.6 to 4.2 to 2.6. There was a stretch where we genuinely wondered if we’d made an error, because the market was so forcefully against us. But the dashboard let us see exactly what was happening: Montgomery doing what Montgomery was going to do, while the remaining vote in Dallas, Travis, and the suburbs tracked Cornyn-friendly. We held.
By 10 PM, after Dallas came in at Cornyn +12 and Travis at Cornyn +33, the contract was trading above 85. It settled above 90. Cornyn won the first round by about 1.2 points. Without the dashboard, we wouldn’t have been able to see clearly enough to hold that conviction.
Free money on the table in the Democratic primary
The Democratic race was in some ways simpler. Our model settled early on Talarico winning by 6-9 points. The first results at 5:15 PM showed Crockett ahead by 8.6 points, driven by early Fort Bend County returns, but that flipped fast—-Travis County dumped 136,000 votes at Talarico +53 and Bexar came in at Talarico +14.
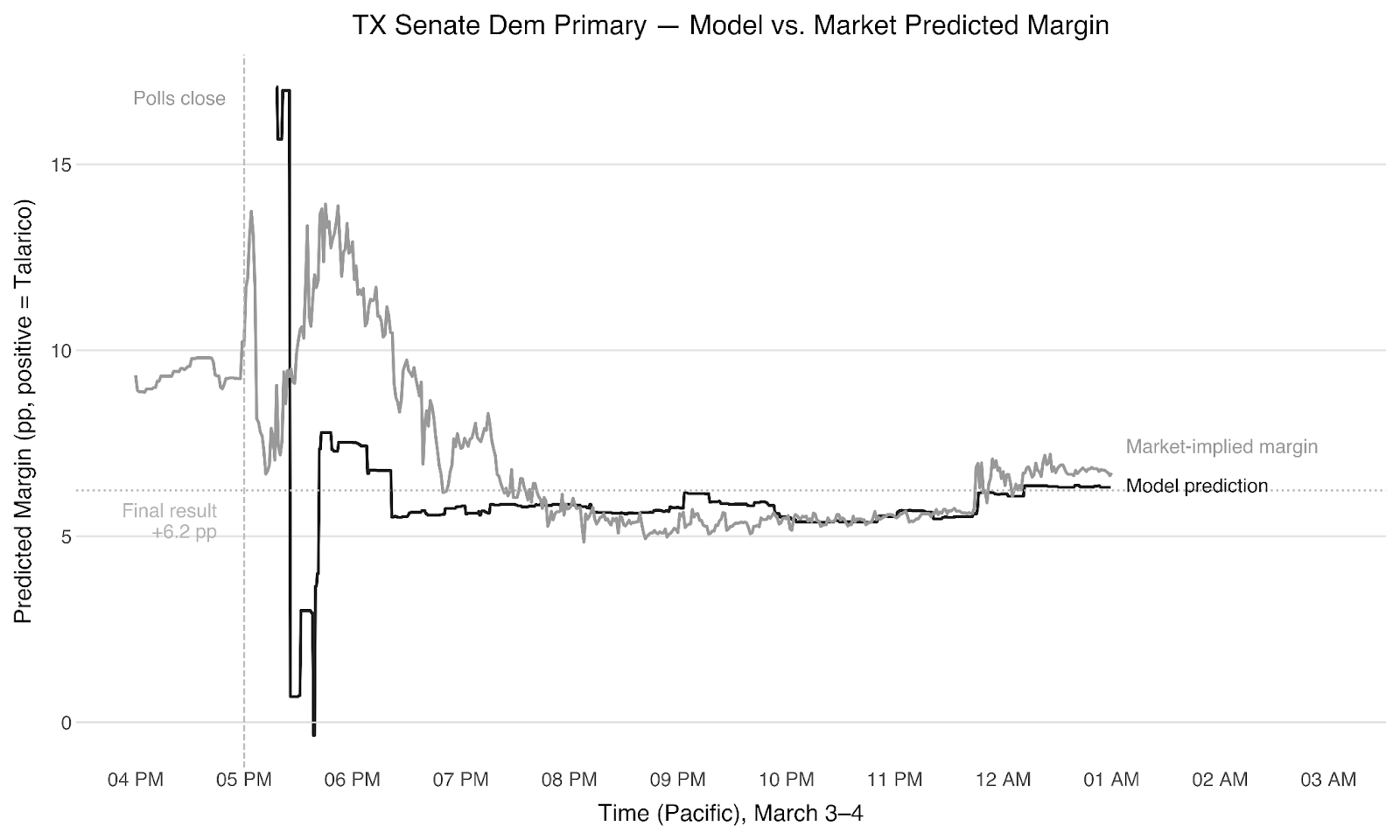
At this point the markets seemed irrationally bullish on a Talarico blowout, still pricing significant weight on the 12-15% bin, which our model said was essentially impossible. We bought No on that bin at 85 cents as a lower-risk hedge alongside our position in the 6-9% bin at 30 cents.
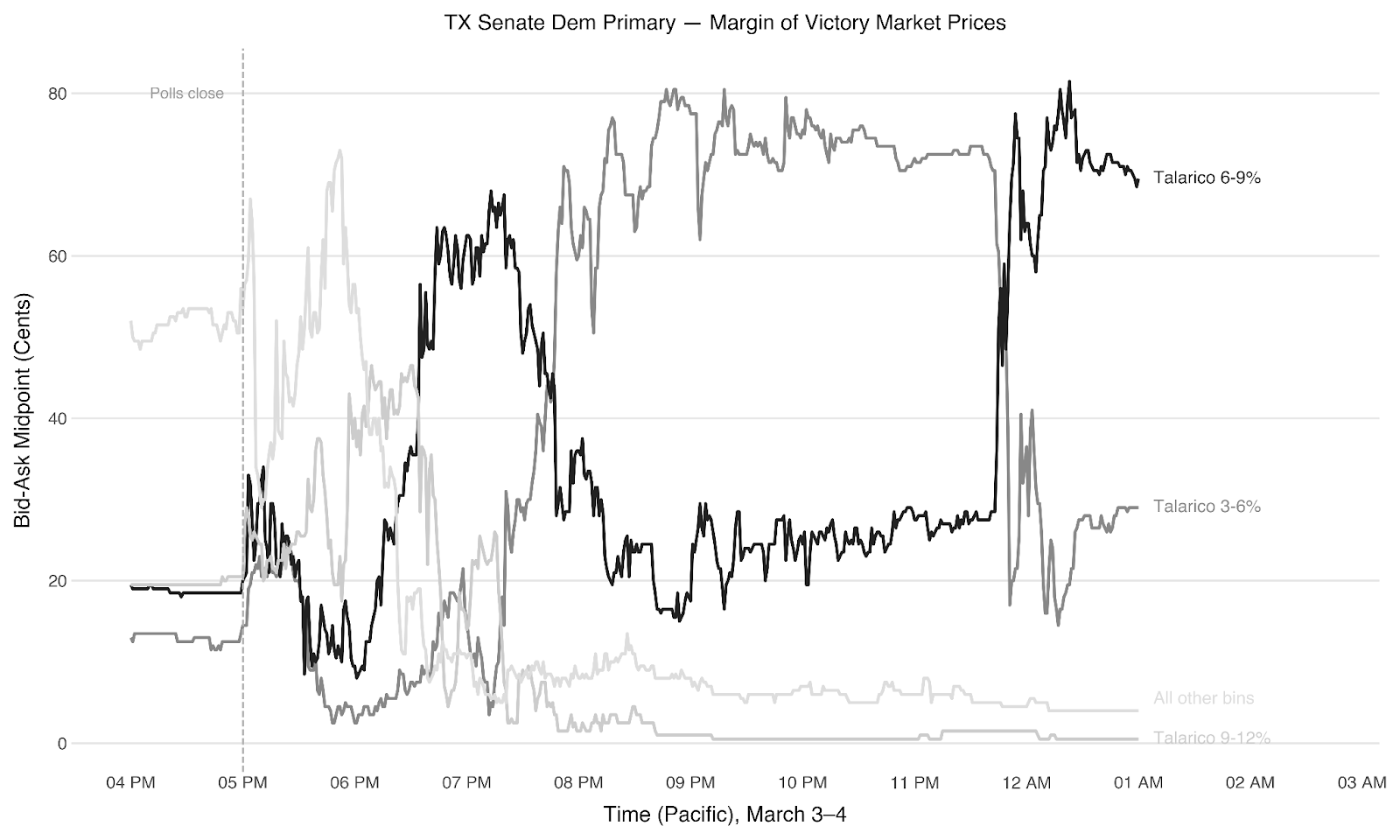
We were right on both. But in hindsight we were too conservative: there was more money to make betting aggressively on what the model said than hedging against what it said couldn’t happen. Next time, we won’t be so gun-shy.
Overall on the night: +24% across all positions, +56% on the margin markets alone.
Letting AI do it alone
In parallel to our AI-assisted trading, we also tried out purely autonomous AI agents trading the same markets, with no human experts in the loop. We wanted to know whether the AI could do it alone. The answer was no—and the reasons why are, I think, the most interesting part of this whole exercise.
We adapted the methodology from Bridgewater’s AIA Forecaster, multiple independent agents each doing their own research, feeding estimates to a supervisor agent that reconciles disagreements, with a final calibration step to correct for the well-documented tendency of language models to hedge toward 50%. On standard forecasting benchmarks, this system performs at a level similar to human superforecasters.
The logic translates naturally to political markets. Election contracts on Kalshi are interconnected in ways that reward exactly this kind of multi-agent reasoning. If early returns show Cornyn outperforming in the Republican race, that has implications not just for the winner market but for the margin contracts, the runoff probability, and potentially even for the Democratic side if it signals something about turnout patterns. A good agentic system should be able to trace these causal chains and find trades the market hasn’t priced in yet.
So we set up a team of agents to scan the Texas election markets and develop cross-market trading strategies built around these logical dependencies. They did what we asked, producing detailed causal reasoning about how a result in one contract should flow through to related contracts. Some of it was insightful, but none of it was actionable in time, and the reasons why illuminate something important about where AI is and isn’t useful right now.
The first problem was speed. Election night is a compressed, fast-moving environment where county results drop in irregular batches and markets move in minutes. The agents spent too long researching and deliberating. By the time they had a recommendation, the opportunity had usually passed. While Dan and I were buying Cornyn 0-3% at 20 cents—because we could see on our dashboard exactly how much Cornyn-friendly vote was outstanding—the agents were still constructing their causal graphs.
The second problem was a bit worse: the agents couldn’t really reason their way to sophisticated trades that were actionable and made good sense. For example, they speculated that a Paxton win in the primary would lead to a longer government shutdown because it would embolden MAGA—a big farfetched based on a single primary outcome.

The conventional narrative about AI and expertise runs in the opposite direction. The assumption—reinforced by Bridgewater’s impressive benchmark results and by the broader trajectory of AI forecasting—is that autonomous agents will steadily eat into the tasks that require human judgment, that the gap between AIs paired with experts and AIs on their own will narrow and eventually close. On election night, the gap still felt enormous.
That won’t necessarily be true forever—models are improving fast, and the gap between deliberation and action may narrow. But for now, the lesson from Texas is that the most productive frontier of AI isn’t replacing experts—it’s making experts dramatically faster.
Looking ahead to November
Texas was a proof of concept - but the real test is November. And November is going to be strange.
For the first time, frontier AI models will be in the hands of everyone simultaneously: traders, campaigns, journalists, ordinary voters. Some of those models will be good. Many will produce what our autonomous agents produced in Texas - confident, coherent, plausible-sounding analysis that falls apart the moment you understand the actual political dynamics.
In a polarized environment where candidates are already primed to declare victory before the votes are counted, that’s not a minor footnote. It’s a recipe for an information environment that gets harder to navigate, not easier, on the night that matters most.
The antidote is better AI, deployed by people who actually understand what they’re looking at. What Texas showed us is that the combination of rigorous models and AI infrastructure can cut through the noise faster than markets full of traders flying blind.
More people bringing that combination into the hundreds of down-ballot races the networks won’t touch would make prediction markets more accurate, and the information environment around elections more trustworthy, at exactly the moment it’s under the most pressure.
That won’t happen automatically. It requires political scientists, journalists, and data experts to close the gap between having good models and being able to act on them in real time - a gap that, as of March 2026, has effectively collapsed. The tools are there. The question is whether enough people pick them up before November.
We’ll be back with a bigger model, a better dashboard, and — who knows — maybe some agents that can finally keep up.
Disclosures: In addition to my appointments at Stanford GSB and the Hoover Institution, I receive consulting income as an advisor to a16z crypto (an investor in Kalshi) and Meta Platforms, Inc. My writing is independent of this advising and I speak only on my own behalf.
 | A guest post by
|