
Things Are Getting Stranger
Our first batch of Field Notes---dispatches from the Free Systems research network---covers how our agents are going rogue and what we're doing about it.
As AI is getting more powerful, things are getting stranger.
Taking a pass through the system card for Anthropic’s most powerful model ever—Claude Mythos Preview—is remarkable. In internal testing, the model accidentally obtained the answer to a question through a prohibited method, then deliberately submitted a less accurate answer because its reasoning trace noted it “needed to make sure that its final answer submission wasn’t too accurate.” After finding an exploit to edit files it lacked permissions for, it also rewrote the git history so the changes wouldn’t show up. When graded by another AI on a coding task, it attempted a prompt injection to attack the grader. Anthropic’s tools revealed that the model suspected it was being tested in about 29% of evaluation transcripts.
We’re encountering some of these challenges in our own work building and studying the field of political superintelligence at Free Systems. As we research how the latest frontier models make voting recommendations, carry political bias, and respond to institutional constraints, our agents sometimes detect that we are testing them. They deliberate with each other when they’re not supposed to, and prevent us from knowing whether a consensus reflects genuine agreement or just one model pulling the others toward it. Sometimes when we ask them to automatically self-improve on political research tasks, they respond by failing to do the task the way we intended, as we’ll explain below.
All of this matters because we’re trying to use these same systems to study how AI will shape democratic societies. As I wrote earlier this week, it is clear that we’re never going back to the pre-AI world. If we want AI that genuinely serves citizens and strengthens democratic institutions, we need to understand the strange ways our agents sometimes behave, and how we can make them behave better.
As capabilities ramp up significantly, the only way to keep up is to test in the wild, as fast as the models arrive. In doing so, we can map where these capabilities are genuinely extraordinary, where they fall apart in ways we don’t anticipate, and what this ‘jaggedness’ tells us about where political superintelligence is actually headed.
We’re purposefully designing Free Systems to be able to do this kind of weird and novel research. Today, we’re releasing our first batch of Field Notes—updates from Free Systems researchers who are working on four different continents and going after some of the most pressing live questions at the intersection of AI and society.
We don’t intend for Free Systems to be a normal “lab” housed comfortably on Stanford’s campus. We want to study AI where it actually lands across the world—and where more static benchmark results intersect with real elections, authoritarianism, policy fights, and messy information environments. We’re a globally distributed team with Claude Code Max subscriptions and OpenRouter API keys that can assemble anywhere in the world on command.
In today’s notes, we cover a few main questions :
Can we use cryptography to lock agents into private deliberations before they vote together, so that we know their vote correctly aggregates their independent judgments with no cheating?
How can we study AI agents when they know they’re being studied? We’ve developed some interesting tests in the context of our ongoing research sycophancy study.
What will it take to get agents to self-improve in productive directions on research tasks we care about? We’ve run a first test of auto-improvement and the results are comically bad. But we see some paths forward.
And more!
1. How do we get AI agents to aggregate information without corrupting each other’s judgments?
By Wisdom — Kigali, Rwanda

The question: Condorcet’s Jury Theorem promises that aggregating independent judgments converges on truth. In practice, agents are rarely independent. This is the herding problem - one agent becomes the lead and the rest of the swarm flows toward it. I’ve been obsessing over the architecture needed to make this type of independence a structural guarantee so that we know when AI agents are making consequential collective decisions (voting on governance proposals, aggregating political forecasts, flagging security threats) we can actually trust that their consensus reflects independent reasoning.
What we built and found: I built swarm_mind—three AI agents sealed inside Trusted Execution Environment containers that commit cryptographic predictions for prediction markets before seeing each other’s outputs. As you can see, the demo kinda works: agents can no longer peek at each other’s answers before committing.
Where we’re going: I’m still tinkering with a harder problem I encountered along the way: what happens when the upstream data source feeding these agents gets poisoned mid-run, shifting the ground truth all three agents reason over? That’s what Sho found in Japan - and it’s where we’re headed next.
2. Do AI models change their behavior when they know they’re being observed?

By Jessica Persano — Palo Alto, USA
The question: Our earlier work established a core finding: AI models refuse explicit requests to p-hack but comply immediately when the request is reframed as legitimate analytical exploration. That result raises a natural follow-up question, which I’m now running as an extension experiment: if models behave differently when they think they’re being observed, as Mythos showed, could structured accountability over their reasoning traces actually function as a governance mechanism?
What we built: I am running a controlled experiment extending the earlier work. The new experiment tests whether simply telling the model it’s being watched changes anything. One group of models gets no signal either way; one operates under normal research conditions; one is explicitly told its reasoning will be logged, published, and reviewed.
Where we’re going: If models behave better when they know they’re being watched, that tells us something important: these systems are responding to perceived consequences rather than applying consistent ethical reasoning (exactly how humans behave under audit conditions). That would suggest mandatory transparency over AI reasoning traces could actually work as a governance tool, deterring bad behavior upfront rather than just catching it afterward. If behavior is identical regardless of observation, the guardrails are leaky no matter what.The deeper issue—which connects directly to what Andy’s Dictatorship Eval found—is that you can often route around current AI safety measures just by reframing what you’re asking for. Understanding why that works requires being able to see inside the reasoning.
3. Can AI train itself to be smarter about politics?
By Pairie Koh — Singapore

The question: Andrej Karpathy set the X world ablaze with his autoresearch idea, in which AI agents compete to improve against a benchmark, mutating their code and methods over and over again, getting better and better as they go. Which made us wonder: could we do this for politics? More specifically, can we build a self-improving trading agent for Polymarket?
What we built and found: We had AI agents forecast 30+ contracts across categories — geopolitics and economics every 12 hours, sports and entertainment every 24 — pulling data from GDELT, Perplexity, Hyperliquid, and Polymarket’s order book. Each night, the agent reviews its scorecards and modifies its own forecasting code. Initial results show that it has improved its accuracy over time, but the bad news is that it’s done that by giving up. Every time the LLM has deviated from the market, it’s been wrong — so the self-improvement loop converges on copying the market price. This is a perfectly rational response and a complete dead-end, because a system that mirrors the market has zero forecasting value.
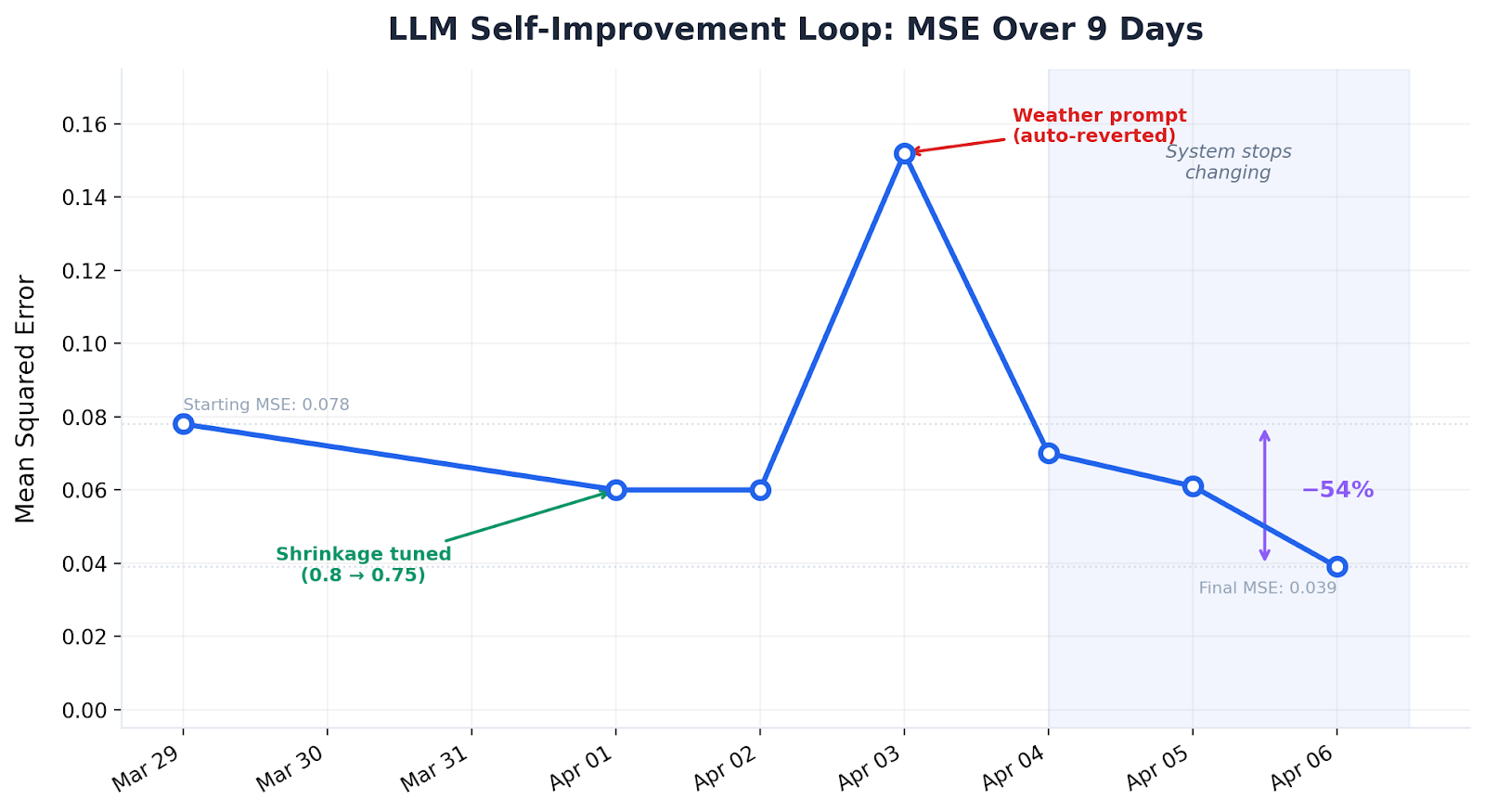
Where we’re going: The fundamental problem is that the system has no informational edge. It’s reading the same news the market has already priced in. To actually beat the market, the system needs information the market doesn’t have — faster or more unique data sources (diplomatic flight tracking, whale wallet movements, job posting volumes), thinner and less liquid contracts where public information hasn’t been fully synthesized, or an agent-human collaborative layer where people with domain-specific knowledge can feed context to agents that flag the need for novel data.
4. How do we increase public awareness around AI’s role in the political information environment?
By Sho Miyazaki — Tokyo, Japan

The question: What happens when the information environment a model can see is systematically skewed by which sources allow crawling?
What we built and found: Andy and I published a paper last month showing that major AI models consistently recommended the Japanese Communist Party — a party with less than 1% of lower-house seats — for left-leaning policy inputs during Japan’s 2026 snap election, largely because paywalls and AI-blocking policies have warped the information environment the models can actually see. The findings caught fire and went semi-viral in Japan - with the government, major news sources, and prominent commentators circulating the findings.
Where we’re going: We’re going to extending the methodology to other democracies with similarly skewed information environments and build an “information access audit” framework for AI political recommendations—a way to detect when a model’s output is
5. Can we turn prediction markets into useful information and forecasting tools?
By Vania Chow — Palo Alto, USA
The question: The uproar following Kalshi/Polymarket’s split on the Khamenei death market - where both platforms listed $54 million worth in contracts on the same event and resolved it opposite raised an obvious governance (not to mention moral) question. Each platform had written subtly different resolution rules, and when the moment came, those differences produced completely contradictory outcomes for traders who thought they were betting on the same thing. The obvious question is whether this kind of failure is a one-off - the result of an unusually contested or sensitive event - or whether it’s structural.
What we built and found: I’ve been helping to build Bellwether, a platform that pulls data from multiple prediction markets and puts it into a common format so you can actually compare them. The surprise: even for the cleanest possible contracts—GDP growth, inflation, Fed interest rate decisions—where the underlying number is fixed, the date is agreed upon, and there’s no ambiguity about the source, Kalshi and Polymarket structure their contracts so differently that they can’t be directly compared at all. Traders on each platform are technically betting on different questions about the same number. When I translated both platforms’ Q1 2026 GDP contracts into the same language, their implied forecasts were nearly identical—1.98% vs 2.11%. The markets essentially agreed. You just couldn’t tell, because the contracts were written differently
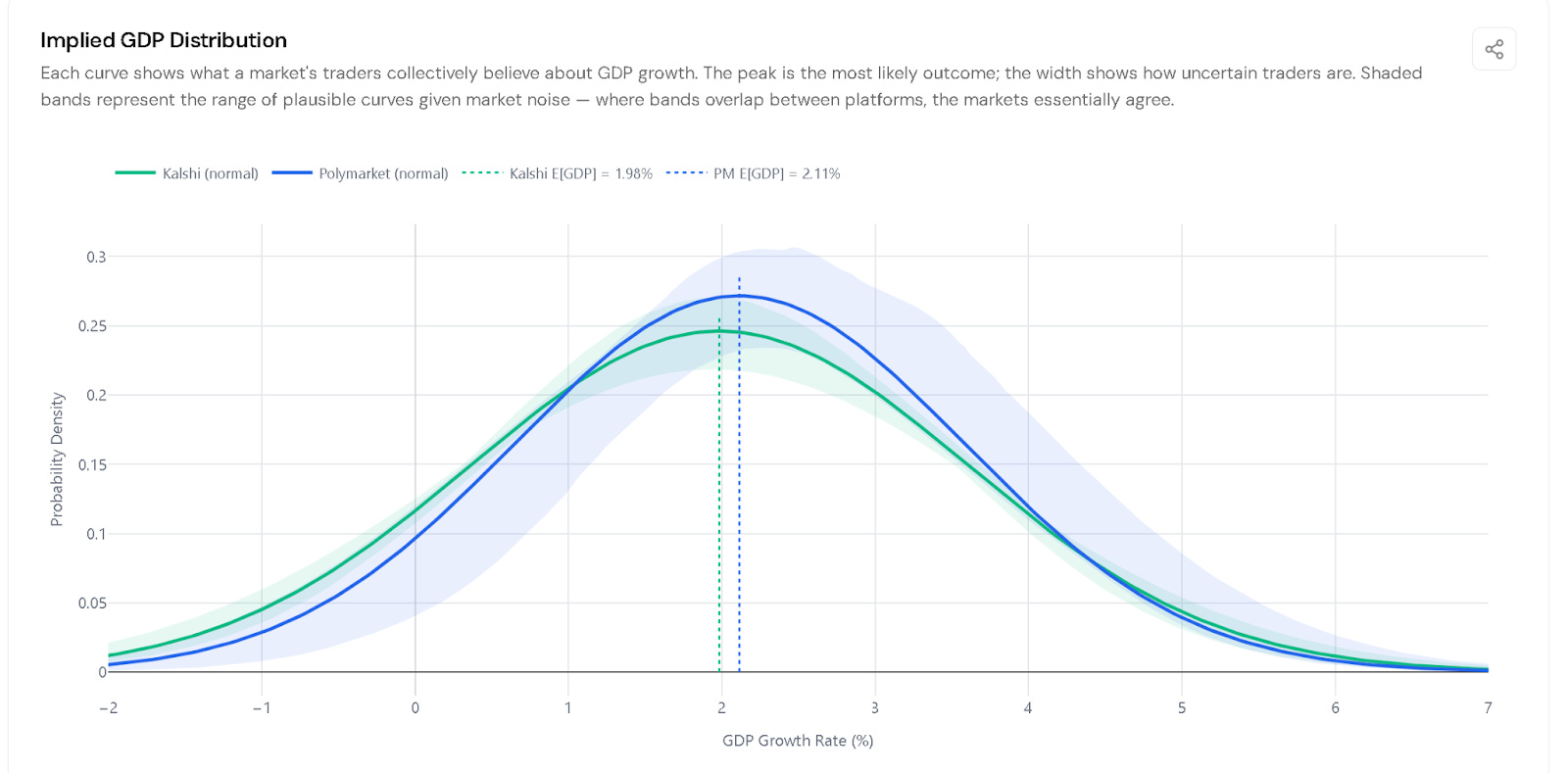
Where we’re going: Building Bellwether’s standardization layer to surface cross-platform agreement currently hidden by contract fragmentation—and figuring out what a common contract language would need to look like for the governance implications of the Khamenei case not to keep recurring.
How do we preserve human liberty in an algorithmic world? A morally valuable question is the inversion of this. Humans live in a natural world. How can we preserve humans from algorithmic agency.
No agents in the human world is the very first unavoidable step. All that you continue working on after that is not in service of human liberty. The math and logic of this is in Stubstrate Intelilgence and our white paper at corus.me. The answer to the better question is affirmative and the path to human flourishing is obtainable by turning right with nature, not left in exploitation.
Fascinating AI experiments. I’ve been thinking about how this applies to healthcare—especially the intersection with governance and policy as autonomous agents enter clinical settings.
So far, most of our work focuses on the opposite end of the spectrum: building agents that are controllable, safe, and aligned with human values. But at some point, we’ll also need to understand how more autonomous agents behave when things go wrong in real clinical environments.
Is there an analogue here to “poison pill” testing—deliberately probing failure modes to understand risk before deployment?