
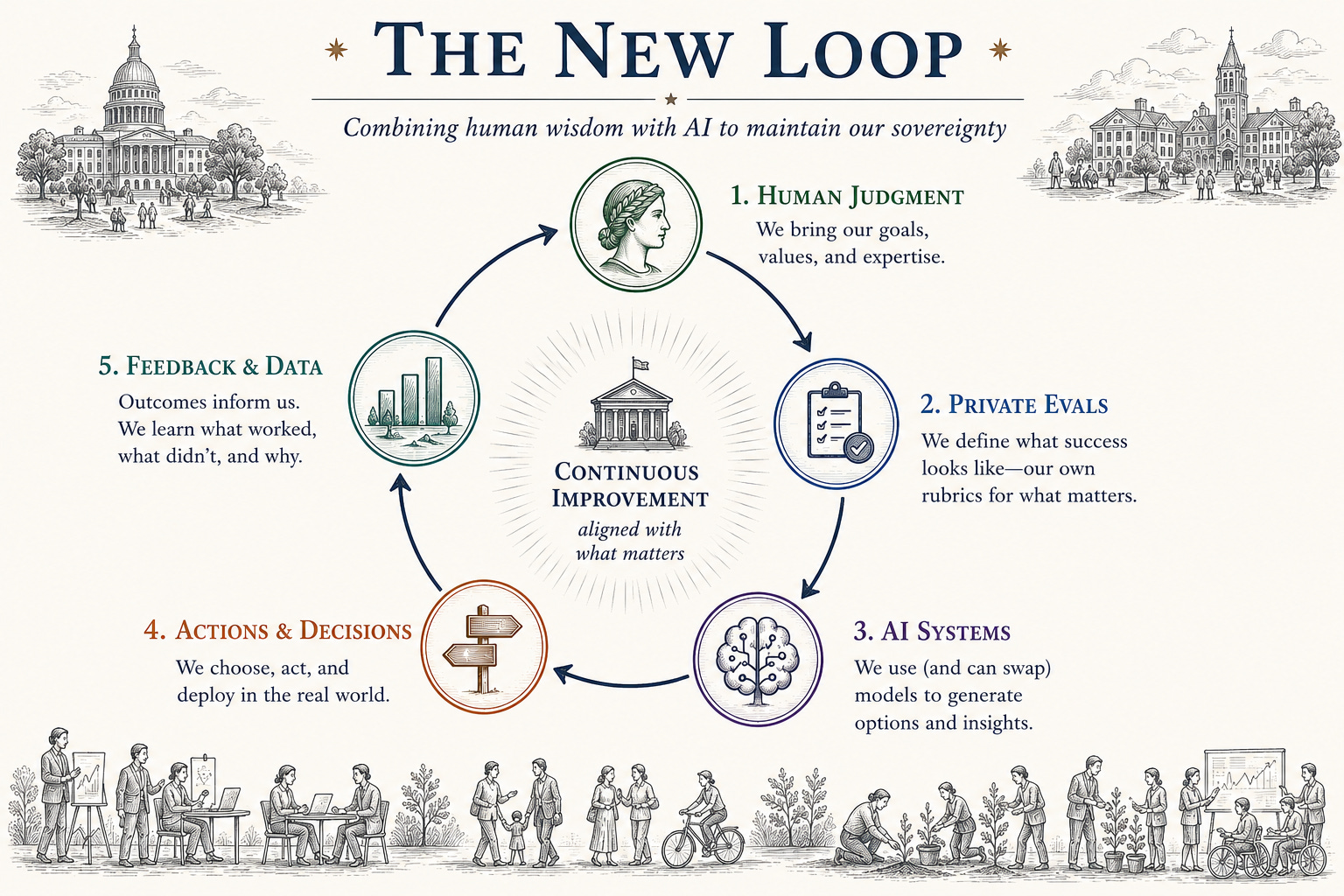
Teaching the New Loop
We must all learn to execute the new loop—to combine our human expertise with AI to produce private evals that measure how well AI is meeting our goals, then hill-climb against this measure.
“Without human direction, you have compute running in circles”
–Satya Nadella
Each frontier AI model release brings surprising new abilities that seem to shorten the list of what makes humans unique and wipe out the startups and established companies that thought they had differentiated themselves from this powerful new technology.
In a remarkable essay published the week before last, Satya Nadella took stock of this state of affairs and asked how any organization can thrive in a world where AI models continuously absorb the expertise of people and companies and sell it back as a commodity. This is not merely a question of business, Nadella tells us, but an existential question of political economy because it implicates the social contract and our shared trust that society can work for us all.
His answer to this conundrum is that firms have to combine their own human expertise with AI to codify their private knowledge inside model evals and training environments that they, and not the frontier labs, own. Nadella envisions a new “loop” where a company transforms its own workflows and accumulated judgment into systems that improve with every use, measuring the result against its own yardsticks rather than the public leaderboards, since, as he puts it,
“Private evals should capture whether a model is actually improving against outcomes that matter to the business.”
These private evals are what enable firms to remain sovereign because it allows them, and not the labs, to own their specialized knowledge. Nadella explains: “A company should be able to switch out a ‘generalist’ model without losing the ‘company veteran’ expertise built into their learning system. This is the key ‘test’ of your control and sovereignty in the era ahead.”
Nadella’s insights go far beyond the firm: indeed, the same opportunity exists throughout society. Think of citizens in a democracy, our political leaders, our universities…we all need a way to harness AI without being absorbed and captured by it. We should all be able to switch out one frontier model for another in our work, and in our lives, without losing our accumulated expertise. This new loop is the way.
So how should we all learn to build it? It’s not something covered in any standard curriculum. But I’m absolutely convinced that it needs to be.
I say this in part because I’ve been experimenting with it in my teaching this year. Just a few weeks before Nadella published his essay calling for companies to build private evals, I had my students in the new “Free Systems” class I’m teaching at Stanford GSB do exactly the same thing. With Claude Code subscriptions, OpenRouter API credits, and a couple of weeks of practice under their belts, my students all created first drafts of their own personal evals in a single three-hour class session.
Each student identified a criterion they cared about—how sycophantic the models were when debating controversial topics, how well the models gave voting advice, whether they understood crucial cultural nuances across languages, and much more—and then designed a rubric for scoring model responses according to their personal beliefs. Then, they built a leaderboard comparing how different leading AI models performed according to their measure. The results were spectacular! But we weren’t done.
Once they could measure models against their own personal yardsticks, we spent the rest of the quarter pushing further—what else could students do with this power? It turns out, a lot. Their final projects give a good sense of what the future that Nadella describes might look like. Together, they look like a nascent field guide to building these new loops in the wild.
What the students did
Here is what that future looked like in our class: fifteen final group projects spanning finance, governance, media, and security, several of them grown straight from the personal evals the students had built a few weeks earlier.
While many of the projects are, at their core, evals, they go beyond the evals we built in class because they’re not just leaderboards; instead, the evals are embedded into broader tools that do something based on the information—whether that’s make a new recommendation, helps the user complete an action, give better advice, and so on. This is how they begin to show us what the new loop will look like.
I’ve grouped them below by theme, with a great deal of help from Claude. You can see all of the projects at this website.
Finance and delegated decision-making
AI Bank Run Simulator (Shang Jing Chia) — live simulation of an AI-driven bank run with LLM agents acting from distinct personas; lets you watch cascades unfold and inspect each agent’s reasoning.
Cross-Market Arbitrage (Graham Griffin, Ethan Romer) — detects informed trading propagating from Polymarket to Kalshi, measuring the lag between the transparent on-chain market and the opaque regulated one.
RegFi Compliance Checker (Bernardo Herzer) — AI tool that automates regulatory compliance checks on financial AI systems to reduce manual review burden.
Media and framing
Headline Truth (Jenna Jokhani) — evaluates whether headlines faithfully represent their articles, and whether models can detect distortion or sensationalism.
A Kaleidoscope for Political Framing (Milly Wong) — paste an op-ed and see where it lands in a 3D map of 284 articles across 7 outlets, embedded in 384 dimensions via UMAP, with separate topic and worldview lenses.
News Framing Dashboard (Eddy Jiang) — feeds one article to Claude, GPT, Gemini, Grok, and Llama and quantifies framing differences across actor salience, affective loading, context inclusion, and hedge density.
Alignment, security, and governance
LLM Imposter: The Council of Five (Raymond Llata) — social-deduction game where one misaligned AI tries to persuade a council of aligned agents to adopt a selfish policy; a proxy for multi-agent alignment robustness.
Steganographic Injection Demo (Yuanxin Ma) — tests 11 hidden-text attack types across 15 frontier models (3,600+ API calls) to see if models can be pushed into biased product rankings.
ChatGPTween (Jaxon Gonzales, Juan Sandoval) — translates parent questionnaires or guided conversations into a personalized AI “constitution” for a child’s chatbot; conversational constitutions refused all 24 adversarial prompts that MCQ-based ones failed.
Personal tools and model selection
Model Signature (Navya Agarwal, Zoya Fasihuddin, Diya Ahuja) — blind A/B/C onboarding across ten task categories builds a personal model-preference heat-map, then routes each query to the best-fit model.
Streamline (Leticia Auriemo, Bennett Evans Zytko, Alec Profit) — conversational sensemaking dashboard that builds a personalized intelligence feed to help users understand complex issues.
Rundown (Prakhar Goel) — connects to Slack and distills a week of channel activity into a one-minute digest.
ResumeScope (Jonas Pao) — resume-review platform where AI recruiter agents simulate how real recruiters read, predicting attention and rating.
Capital concentration and AI infrastructure
Situational Unawareness (Vivek Yarlagedda, Kathy Shao, Shawn Gregory, George Zhang) — interactive map of the AI stack covering 92 companies and 297 deals, filterable by layer (compute, networking, raw materials, power, capital) and deal type to trace where deal flow concentrates.
The Hidden Cost of AI (Natalie Hampton, Quincy Stone) — map of where AI compute is physically concentrated and which communities absorb the water, electricity, land, and pollution costs; reports 86% of mapped capacity in wealthy hubs and 70% of 2024 data-center electricity used by the US and China.
What I learned
I drew four main lessons from this first experiment in teaching the new loop.
Lesson 1: Human expertise and critical thinking is an essential pre-requisite
The projects succeeded in large part because they were based on things the student already knew and cared deeply about. Far from letting students outsource their thinking, the work demanded more of it, which is why the familiar worry that AI erodes critical thinking has it backwards here, where critical thinking is the thing that makes the AI worth anything at all. This implies that we can’t only offer AI-intensive classes in the university of the future; instead, we need these classes to come after classes that teach essential critical thinking skills and domain knowledge.
Lesson 2: Students need a ramp and tangible examples
Nobody walks in and commands a fleet of agents effectively on the first day. Students need a ramp, structured early assignments and concrete examples they can imitate before they strike out on their own. What looks from the outside like sudden fluency is really careful sequencing, giving people just enough scaffolding to find their footing and then taking it away once they have it.
Lesson 3: In-person collaboration and tutoring is crucial
I found that the work goes far better when students are in the same room, where they can look over a shoulder, borrow a trick someone two seats away just figured out, and get unstuck the moment they are stuck rather than three days later by email. A live tutor who can diagnose a broken agent in thirty seconds is worth more than any amount of documentation, because the failures these tools throw are still strange enough that a person rarely knows the right question to ask on their own.
Lesson 4: Everyone needs the right push to get started
The most important thing I observed was that many people don’t know what they don’t know—they assume it will be far harder to master the new loop than it actually is, and that assumption prevents them from getting started. Having an easy, low-pressure way to jump start their own experiments helps get people moving.
The Republic of builders

Although Nadella’s essay is primarily a business essay, it can also be read as a piece of political economy. He worries about a future in which AI models “eat everything they see” and predicts that such a world will not lead to a sustainable political equilibrium. “There is no societal permission for an AI future that hollows out entire industries,” he warns us.
Instead, he argues that if firms can build their new loops, then they “will create value for themselves and for the economy around them. Employees will see their expertise amplified and their judgment become part of systems that make it replicable and scalable and the benefits accrue to the companies and communities around them.”
This is the ecosystem we’ll need to sustain a free society in the AI era. We need everyone to be able to use AI, measure it according to their private evals, update accordingly, and capture value. In a way, this is the oldest argument for educating a free people, just refreshed. Writing in 1822 to a legislator who was building Kentucky’s public schools and university, James Madison put it plainly: “a people who mean to be their own Governors, must arm themselves with the power which knowledge gives.” The loop is how a free people arms itself now, and a citizen who can neither wield these systems nor measure them for herself has simply handed that power to whoever owns the models.
Therefore, I want every person in the world to learn how to do this. We need to teach executives and MBAs, college students, and even high school students how to do this. We don’t only need “an army of citizens building evals” as I put it previously; we need that army to also understand how to turn those evals into concrete tools and decisions that make AI work for us, instead of vice-versa.
That’s a big ambition, and I’ll be taking it in steps. Next year, I’ll be offering a set of new courses for executives, MBAs, and undergrads entitled “AI Tools for Leaders” that aims to teach people this new loop. If we can succeed, I hope we can expand it beyond Stanford, and I hope that many others will be developing similar ideas and experiments in parallel all across the world, so that we can all benefit from the new loop and make sure that frontier models don’t eat us all.
Andy - you invited parallel experiments, so here's one. I've spent the past several months building a version of this loop for myself with Claude Code as the engine, and the experience pulled me toward Nadella's framing of it more than the eval-centered one.
The difference is in what the loop is for. An eval produces an artifact - a rubric, a leaderboard, a score. Genuinely useful, and a great on-ramp (your Lesson 2). But what I ended up building isn't an artifact; it's a feedback-producing process, and its only product is a better thinker over time - me. That's Nadella's "you can never offload your learning" taken literally: the goal isn't to measure a model, it's to compound my own judgment.
Structurally that needs two things an eval doesn't:
1. An owned, model-agnostic substrate - local files, my own version control, memory that isn't in a vendor's profile. Nadella's sovereignty test (swap the model, lose nothing that matters), pointed at a person instead of a firm.
2. A memory that remembers me, not just my rubric - so the loop can surface my own inconsistencies ("you argued the opposite in March") and connect today's reading to two years of accumulated content. A rubric is my current judgment reified; it can't catch my own drift. Only a record of past selves can.
And it can't be built in an afternoon - only started and run. The value is in the years.
So for a class, maybe the eval is the ramp and the compounding feedback loop is the destination. If the goal is better thinkers, that's the shape I'd point students toward.